I have been looking to write a post like this for some time but have been unable to get the definitive data that I needed to show the core costs associated with poor LPAR Affinity. We recently ran some load testing using Load Runner and the same workload was applied to four different LPARs with the exact same configuration.
The tests were conducted on p7 795 hardware.
These tests highlight the negative effects from having high vCPU counts and low Entitlements on a p7 795.
We had two LPARs running on the same Node in one Frame and the other two LPARs running on separate Nodes in another Frame.
LPAR Details - All LPARs identical.
AIX: 7100-04-03-1642
Shared-SMT (smtctl -t 2)
schedo vpm_throughput_mode = 2
Entitlement = 3.0
vCPU Count = 30
Memory = 40960 Megabytes - Dedicated.
p7 Details.
9119-FHB ==> p795
Clock Speed: 4004 MHz
All 256 Cores are activated.
Processor Implementation Mode: POWER 7
Firmware Version: AH780_068
Test Summary.
The testing injects over 1,400 transactions per second to the LPARs using load running. This ensures that the same load is allocated to each LPAR.
Test on p7.
LPAR1 was on Node 5 in Frame 1.
LPAR2 was on Node 7 in Frame 1.
LPAR3 was on Node 5 in Frame 2.
LPAR4 was on Node5 in Frame 2.
Shared Processor Pool Consumption.
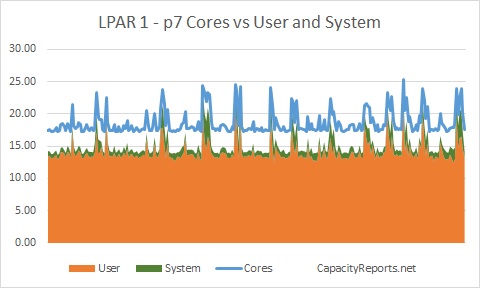
LPAR1 around 17 to 18 cores.
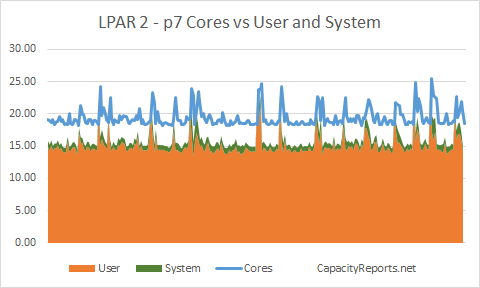
LPAR2 around 18 to 19 cores.
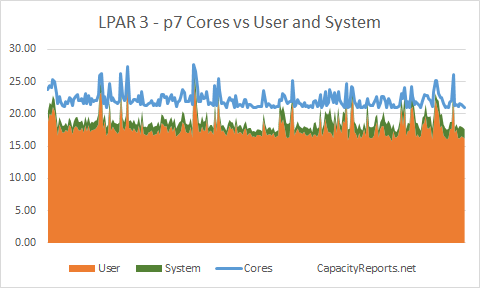
LPAR3 around 21 to 23 cores.
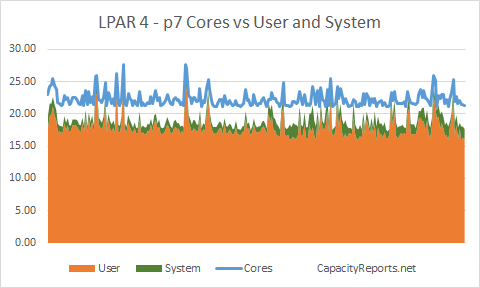
LPAR4 around 21 to 23 cores.
A point to note here is that on a p7-795 with all cores activated, there are 32 cores available per node. Therefore, LPAR3 and LPAR4 were consuming (at minimum) a combined total of 42 cores, which means that some of their virtual processors (VPs) were scheduled to a far node. I believe this is the reason why they are consuming around 22% more cores than LPAR1 whose VPs were running within the same Node, as there is extra CPU overhead in copying/syncing cache content between cores on far nodes.
LPAR1 Cores to User and System
LPAR2 Cores to User and System
LPAR3 Cores to User and System
LPAR4 Cores to User and System
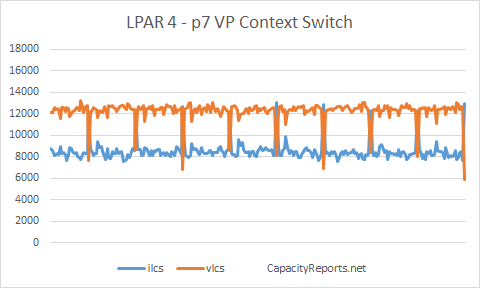
Virtual Processor Context Switching.
ilcs is the number of involuntary logical processor context switches. VP was kicked off the core by the Hypervisor due to another LPAR running under entitlement needing to run on the core.
vlcs is the number of voluntary logical processor context switches. VP was voluntary ceeded back to the shared pool as the LPAR did not have any active workload to run on the core.
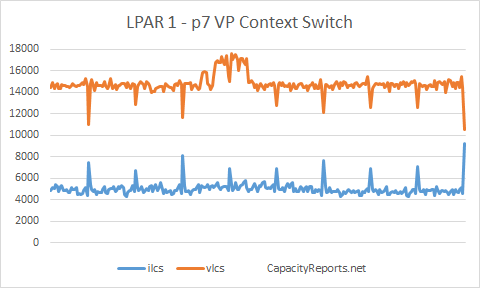
LPAR1 shows around 5,000 ilcs and 14,600 vlcs.
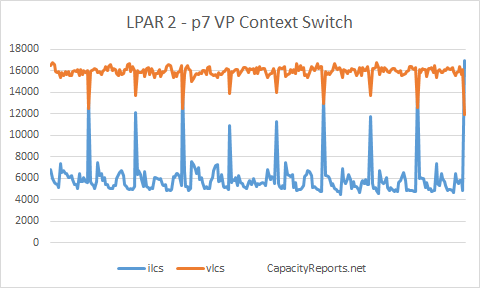
LPAR2 shows around 6,000 ilcs and 15,700 vlcs.
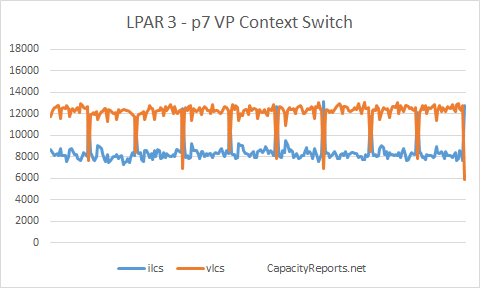
LPAR3 shows around 8,500 ilcs and 12,000 vlcs.
LPAR4 shows around 8,600 ilcs and 12,000 vlcs.
LPAR3 and LPAR4 are showning around 40% more ilcs's than LPAR1, meaning they are being kicked off the core (with a running workload) more often.
LPAR3 and LPAR4 are showing around 18% less vlcs's that LPAR1, meaning they are not ceeding idle cores back to the shared pool as often.
LPAR1 ilcs to vlcs
LPAR2 ilcs to vlcs
LPAR3 ilcs to vlcs
LPAR4 ilcs to vlcs